事前機械学習モデル FaceMesh を使う
カメラが捉えた画像内の顔の部位の位置に応じた処理をするp5.jsのスケッチを作成してみましょう。ml5.jsライブラリは、カメラ画像を認識して、人のポーズや顔のパーツの位置を検知するための、事前機械学習モデルを提供しています。
ここでは Facemeshを使ってみます。 ml5.jsは、Googleが開発した機械学習システムTensorFlowを活用して開発されており、自分のスケッチに機械学習機能を組み込み、簡単な「AI」プログラムを作ることを助けるライブラリです。
ml5.jsライブラリを使うために、次のscriptタグをindex.html内に指定します。
<script src="https://unpkg.com/ml5@1/dist/ml5.js"> </script>ネットワークを経由してライブラリを配信する仕組みであるCDN(Contents Delivery Network)のサイトを通じて、ml5.jsライブラリを参照する指定です。
Facemeshの使い方
Facemeshは入力された画像(静止画や動画)から、人の顔の部分の位置を推定する機械学習モデルです。顔の468の位置を推定します。 入力画像内で最大何人の顔を検知するかをパラメータで指定できます。コンピュータに接続されたカメラの入力画像から、人の顔を推定するサンプル(リスト9-1)をもとにFacemeshの使い方を説明します。(1) Facemeshの初期化(Facemeshを作る)
preload()関数内で、ml5.facemesh()を使って、Facemeshを作ります。第1引数には入力の映像を、第2引数にはFacemeshが準備できたら呼び出される関数を指定します。
let facemesh;
function preload() {
facemesh = ml5.faceMesh();
}
faceMesh()の引数に、検出する顔の数を
オプションとして指定できます。(2) ビデオ映像の設定
createCapture()関数を使って、コンピュータに接続されたカメラの映像を得るするためのオブジェクトを作成します。createCapture()関数が返すオブジェクトはp5.Elementで、HTMLの <video>タグで作られる要素に対応します。
キャプチャした映像は、image()関数を使ってキャンバスに描画できます。
createCapture()の第1引数では、キャプチャする対象が、画像(VIDEO)か音声(AUDIO)かを指定します。省略すると両方をキャプチャします。
let video;
function setup() {
createCanvas(640, 480); //キャプチャした画像を表示するキャンバス
video = createCapture(VIDEO);
video.size(width, height); //キャプチャする画像の大きさをキャンバスと同じにする
video.hide(); //キャプチャされた映像を表示しない
....
}
キャプチャされた映像は、デフォルトで表示される仕様になっており、それを止めるにはcreateCapture()関数が返すオブジェクトに対してhide()メソッドを実行します。(3) Facemeshにコールバック関数を設定する
videoの検知を開始し、顔を検知したら実行する処理をdetectStart()メソッドで指定します。 推定'predict'を認識したらどのような処理をするかをコールバック関数内に定義します。
function setup() {
....
facemesh.detectStart(video, gotResult);
}
(4) コールバック関数の定義コールバック関数の引数は、顔を検知した結果の配列です。リスト9-1のコールバック関数gotResult()内では、引数で渡される推定結果をグローバル変数のfacesに代入しています。
let faces = [];
function gotResult(results){
faces = results;
}
引数resultsの配列内には、検知した顔の数の連想配列が要素として入っています。それぞれの連想配列には、次のようなキーが含まれます。
[ {
box: 値, //顔を囲む矩形
faceOval: 値, //顔の中心位置、幅、高さ、輪郭
keypoints: 値, //顔の468地点の座標
eyeleft: 値, //顔の特定部位の位置、大きさ
....
},
{ .... } // 2つめの顔
]
連想配列はキーと値をコロンで繋いだセットからなり、そのセットをカンマで区切って並べ、{と}で囲んだ形をしています。
{ キー1: 値1, キー2: 値2, ……}
連想配列の値を取り出すには、ピリオドの後ろにキーを指定する(連想配列.キー、これをドット記法といいます)か、キーを配列のインデックスとして指定します(連想配列["キー"])。
{ キー1: 値1, キー2: 値2, ……}
連想配列の値を取り出すには、ピリオドの後ろにキーを指定する(連想配列.キー、これをドット記法といいます)か、キーを配列のインデックスとして指定します(連想配列["キー"])。
(5) 検知した顔情報
顔を検知した時、コールバック関数の引数で渡される連想配列のkeypointsには、顔の468の部位(ランドマーク)の座標[x, y, z]が入っています。
0: {x: 233.58046943424725, y: 268.060638993213, z: -5.87644141926423, name: 'lips'} //上唇の中央
1: {x: 235.12616098374173, y: 259.44993637044297, z: -13.355172181584678}
2: {x: 233.95676581354638, y: 261.6143254957773, z: -6.344661085525133}
3: {x: 232.30245489268844, y: 248.69973571782776, z: -11.15261587518704}
4: {x: 235.29972861131893, y: 256.42192493039425, z: -14.471184785192053}
5: {x: 235.0389961239077, y: 252.06278011745957, z: -13.787136731503914}
6: {x: 233.8506029641535, y: 241.28676803175682, z: -7.902822336221876}
7: {x: 213.07647293295707, y: 237.99038408832243, z: -0.42344036005546914, name: 'rightEye'}
8: {x: 233.47987188254692, y: 234.6289808194376, z: -6.775227730086376}
9: {x: 233.58443049000596, y: 230.9409922542565, z: -7.702565232864668}
......
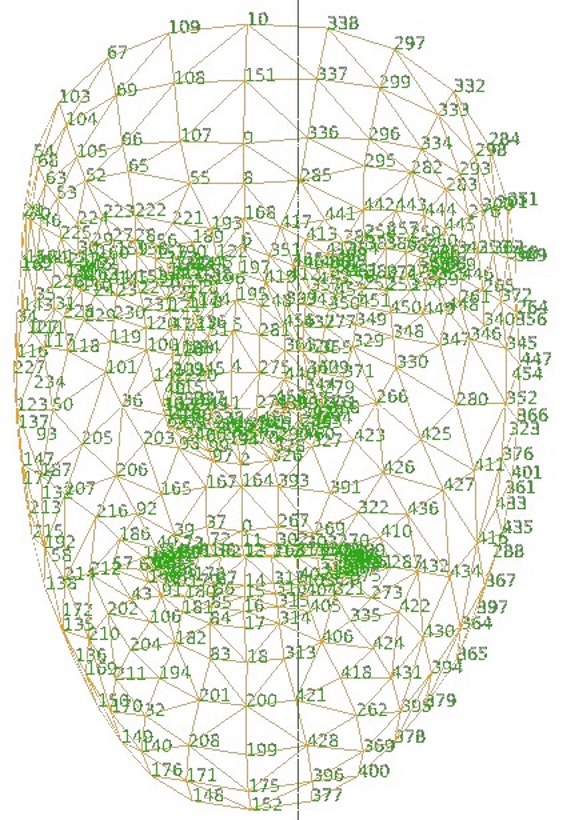
インデックスと部位の対応の一部を示します。
0: 上唇の中央上 1: 鼻の高い位置 2: 鼻下 10: 額中央上部 16: 下唇中央上 133: 右目頭 362: 左目頭例えば、一人めの顔の鼻下の位置は次のように得られます。
x座標は、faces[0].keypoints[2].x y座標は、faces[0].keypoints[2].y
コールバック関数の引数で渡される連想配列にはkeypointsに加えて、顔の特定の部位(leftEye, leftEyebrow, lips, rightEye, rightEyebrow)の位置、高さ、幅を格納した要素も含まれます。次は、キーleftEyeの値の例です。
leftEye: { centerX: 132.94942730900402, //左目の中央
centerY: 281.49971072568525,
height: 4.916166155971609,
keypoints: (17) [{…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}],,
width: 13.670839679431822
x: 126.11400746928811, //左上すみの位置
y: 279.04162764769944 }
【リスト9-1】
let facemesh;
let video;
let faces = [];
function preload() {
facemesh = ml5.faceMesh();
}
function setup() {
createCanvas(640, 480); //キャプチャした画像を表示するキャンバス
video = createCapture(VIDEO);
video.size(width, height); //キャプチャする画像の大きさをキャンバスと同じにする
video.hide(); //元のビデオ画像を表示しない
facemesh.detectStart(video, gotResult); // 顔を検知(予測)した時実行される関数を設定
}
function gotResult(results){ // 顔を検知(予測)した時実行される関数を定義
faces = results; // 検知結果をグローバル変数faceに代入
}
function draw() {
image(video, 0, 0, width, height);
drawKeypoints(); //すべてのkeypointを描く
}
function drawKeypoints() { // 検知されたキーポイントに円を描く関数
for (let i = 0; i<faces.length; i++) {
let face = faces[i]; //検知された顔から順に一つ取り出す
for (let j = 0; j < face.keypoints.length; j++) { // 468のポイントに円を描く
let keypoint = face.keypoints[j];
fill(255, 0, 255);
circle(keypoint.x, keypoint.y, 5);
}
}
}
Facemeshを使って遊ぶ
Facemeshで検知された顔の上に、別のグラフィックを描いて、人の動きに応答する画像を作り出すスケッチを作ってみます。 リスト9_2は、検知した顔の上に目と唇を描いたスケッチです。
【リスト9-2】
let facemesh;
let video;
let faces = [];
function preload() {
// Load the faceMesh model
facemesh = ml5.faceMesh();
}
function setup() {
createCanvas(640, 480); //キャプチャした画像を表示するキャンバス
video = createCapture(VIDEO);
video.size(width, height); //キャプチャする画像の大きさをキャンバスと同じにする
video.hide(); //元のビデオ画像を表示しない
facemesh.detectStart(video, gotResult);
}
function gotResult(results) { // 新しい検知(予測)がされるごとに実行される関数を定義
faces = results; // 検知結果をグローバル変数facesに代入
}
function draw() {
image(video, 0, 0, width, height);
drawEyeMouth(); //目と唇を描く
}
// 検知された顔の上に目と唇を描く関数
function drawEyeMouth() {
for (let i = 0; i<faces.length; i++) {
let keypoints = faces[i].keypoints;
//目頭間の距離 目の大きさの調整に使う
let haba = dist(keypoints[362].x, keypoints[362].y, keypoints[133].x, keypoints[133].y);
noStroke();
fill(255);
circle(keypoints[386].x, keypoints[386].y, haba); //左
circle(keypoints[159].x, keypoints[159].y, haba); //右
fill(0);
circle(keypoints[386].x, keypoints[386].y, haba/2); //左
circle(keypoints[159].x, keypoints[159].y, haba/2); //右
let lipsOuter = faces[i].lips.keypoints;
noFill();
strokeWeight(10);
stroke(200, 0, 0);
for (let i=0; i<lipsOuter.length; i++) { //唇をドットで描く
point(lipsOuter[i].x, lipsOuter[i].y);
}
}
}
演習問題
【問題9-1】Facemeshを使い、カメラが捉えた顔の表情(顔のパーツの位置)に応じた処理をするp5.jsのスケッチを、独自のアイディアに基づいて作成してみよう。
一つの例を次に載せます。 喜怒がふる